American Business Pattern
Tian Wen
Introduction
Business is the cornerstone of prosperity in society. Companies create the resources that permit social development and welfare. In the background of number of companies is growing bigger and changing rapidly, we can not know structure of their distribution among industries if we do not conduct effective analysis.
In order to get to understand business pattern in the society and support questions such as which states are with the largest scale of business, what is payroll status of different industries like, what are the competitive industries of New York state, this study is designed to help.
It is intriguing and meaningful to explore deep into massive data to get holistic perception of the society’s business status and comprehensive understanding of some particular industries. In this study, figures and interactive graphics will be produced to get knowledge about industries status among different states using indexes like employment, annual payroll and number of firms. The relationship between employment and annual payroll will be discussed. Industries development status in New York state will be focused on. And actual data will be used to identify spatial autocorrelation of information industry.
Materials and methods
Packages
Here are all the packages needed for the project:
library(readxl)
library(ggplot2)
library(highcharter)
library(dplyr)
library(viridisLite)
library(forecast)
library(treemap)
library(flexdashboard)
library(leaflet)
library(sp)
library(geojson)
library(geojsonio)
library(rgdal)
library(foreach)
library(rbokeh)
library(plotly)
library(raster)
library(spdep)
library(knitr)
library(sf)
library(widgetframe)
knitr::opts_chunk$set(cache = TRUE) # cache the results for quick compilingData
Original data including American Annual Payroll and Employment by states (2015), American Annual Payroll and Employment among industries by states (2015), the US states polygon data (geojson). Modifications are made to make these data more suitable for the project.
1. Total number of firms among different states:
if (!file.exists("./data/total_2015.xlsx"))
{
download.file("https://www2.census.gov/programs-surveys/susb/tables/2015/us_state_totals_2015.xlsx",destfile = "./data/total_2015.xlsx",mode="wb")
}
dataset <- read_excel("./data/total_2015.xlsx",1,skip=16)
colnames(dataset) <- c("FIPS","Geo_Des","Emp_Size","NFirms","NEst","NEmp","Flag","Ann_Pay","Ann_Flag")
subset <- dataset[dataset$Emp_Size=="01: Total",]
knitr::kable(head(subset), caption = "") | FIPS | Geo_Des | Emp_Size | NFirms | NEst | NEmp | Flag | Ann_Pay | Ann_Flag |
|---|---|---|---|---|---|---|---|---|
| 01 | Alabama | 01: Total | 73409 | 98540 | 1634391 | G | 67370353 | G |
| 02 | Alaska | 01: Total | 16952 | 20907 | 267999 | G | 15643303 | G |
| 04 | Arizona | 01: Total | 105004 | 136352 | 2295186 | G | 102671393 | G |
| 05 | Arkansas | 01: Total | 50451 | 65175 | 1003113 | G | 39451191 | G |
| 06 | California | 01: Total | 740303 | 908120 | 14325377 | G | 856954246 | G |
| 08 | Colorado | 01: Total | 133930 | 161737 | 2253795 | G | 117539555 | G |
2. Geojson Data with interested industries:
df <- read.csv(file="./data/ann_industry.csv",header=TRUE,skip=2)
colnames(df) <- c("GEOID","ID","GEO_NAME","NAICS","INDUSTRY","YEAR","ESTAB","EMP","PAYQ1","PAYANN")
url <- "http://leafletjs.com/examples/choropleth/us-states.js"
doc <- readLines(url)
doc2 <- gsub("var statesData = ", "", doc)
fn<-tempfile()
write(doc2,fn)
write(doc2, file = "data/us-states.geojson")
poly <- readOGR(dsn=fn)## OGR data source with driver: GeoJSON
## Source: "C:\Users\timwe\AppData\Local\Temp\Rtmpiw2HnI\file303c255d6afe", layer: "file303c255d6afe"
## with 52 features
## It has 3 fieldsstates <- geojsonio::geojson_read("data/us-states.geojson", what = "sp")
for(i in 1:nrow(poly))
{
poly[i,'Agriculture'] <- as.numeric(df[which(df$GEO_NAME==as.character(poly[i,]$name) & df$INDUSTRY=='Agriculture, forestry, fishing and hunting'),][1,10])
poly[i,'Utilities'] <- as.numeric(df[which(df$GEO_NAME==as.character(poly[i,]$name) & df$INDUSTRY=='Utilities'),][1,10])
poly[i,'Manufacturing'] <- as.numeric(df[which(df$GEO_NAME==as.character(poly[i,]$name) & df$INDUSTRY=='Manufacturing'),][1,10])
poly[i,'Information'] <- as.numeric(df[which(df$GEO_NAME==as.character(poly[i,]$name) & df$INDUSTRY=='Information'),][1,10])
poly[i,'HealthCare'] <- as.numeric(df[which(df$GEO_NAME==as.character(poly[i,]$name) & df$INDUSTRY=='Health care and social assistance'),][1,10])
poly[i,'Arts'] <- as.numeric(df[which(df$GEO_NAME==as.character(poly[i,]$name) & df$INDUSTRY=='Arts, entertainment, and recreation'),][1,10])
}3. Status of industries among different states:
df2 <- read.csv(file="./data/ann_industryc.csv",header=TRUE)
colnames(df2) <- c("GEOID","ID","GEO_NAME","NAICS","INDUSTRY","YEAR","ESTAB","EMP","PAYQ1","PAYANN")
knitr::kable(head(df2), caption = "") | GEOID | ID | GEO_NAME | NAICS | INDUSTRY | YEAR | ESTAB | EMP | PAYQ1 | PAYANN |
|---|---|---|---|---|---|---|---|---|---|
| 0400000US04 | 4 | Arizona | 3364 | Aerospace product and parts manufacturing | 2015 | 79 | 19795 | 514076 | 1900315 |
| 0400000US04 | 4 | Arizona | 11 | Agriculture, forestry, fishing and hunting | 2015 | 203 | 1610 | 14158 | 56552 |
| 0400000US04 | 4 | Arizona | 481 | Air transportation | 2015 | 109 | 17052 | 331345 | 1254002 |
| 0400000US04 | 4 | Arizona | 336411 | Aircraft manufacturing | 2015 | 9 | h | D | D |
| 0400000US04 | 4 | Arizona | 451211 | Book stores | 2015 | 141 | 1811 | 6038 | 24646 |
| 0400000US04 | 4 | Arizona | 51 | Information | 2015 | 2121 | 49040 | 904992 | 3551580 |
Methods
Different kinds of interactive visualization, spatial autocorrelation are used as main methods in the project.
Results
Numbers of Firms by State
Scale of business among states can be somehow recognized based on the number of firms. Interactive map showed below provides preliminary knowledge of business scale.
thm <-
hc_theme(
colors = c("#1a6ecc", "#434348", "#90ed7d"),
chart = list(
backgroundColor = "transparent",
style = list(fontFamily = "Source Sans Pro")
),
xAxis = list(
gridLineWidth = 1
)
)
n <- 4
colstops <- data.frame(
q = 0:n/n,
c = substring(viridis(n + 1), 0, 7)) %>%
list_parse2()
highchart() %>%
hc_add_series_map(usgeojson, subset, name = "Number of Firms",
value = "NFirms", joinBy = c("woename", "Geo_Des"),
dataLabels = list(enabled = TRUE,
format = '{point.properties.postalcode}')) %>%
hc_colorAxis(stops = colstops) %>%
hc_legend(valueDecimals = 0, valueSuffix = "%") %>%
hc_mapNavigation(enabled = TRUE) %>%
hc_add_theme(thm)Payroll and Employment
Two interactive figures showed below are to provides some more detailed knowledge of business scale among states based indexes of annual payroll and employment. The first fugure uses area of polygon to represent the number of annual payroll and the unit is 1000 dollars. The second figure lists states with top 10 employment. It is easy to find that ranks of annual payroll and employment are similar.
Annual Payroll by State
tm <- treemap(subset, index = c("Emp_Size", "Geo_Des"),
vSize = "Ann_Pay", vColor = "Ann_Pay",
type = "value", palette = rev(viridis(6)),title="2017 Annual Payroll of all firms by state")
highchart() %>%
hc_add_series_treemap(tm, allowDrillToNode = TRUE,
layoutAlgorithm = "squarified") %>%
hc_add_theme(thm)Total Employment by State (Top 10)
set.seed(2)
nprods <- 10
barData <- subset[order(subset$NEmp,decreasing=TRUE),][1:10,]
barData %>%
.$Geo_Des %>%
rep(times = barData$NEmp) %>%
factor(levels = unique(.)) %>%
hchart(showInLegend = FALSE, name = "NEmp", pointWidth = 10) %>%
hc_add_theme(thm) %>%
hc_chart(type = "bar")Relationship between Payroll and Employment
From the analysis above, phenomenon that ranks of annual payroll and employment are similar is found. Hypothesis that annual payroll and employment are positive correlated can be come up with. In order to judge the correctness of the hypothesis, annual payroll and emplyment data of 18 states is used to figure out rules between annual payroll and employment. Axix-X shows the number of employment and axix-Y shows the number of annual payroll. Different shapes of points represent data in different state.
figure(width=800,height=800) %>%
ly_points(EMP,PAYANN,data=df2,color=GEO_NAME,glyph=GEO_NAME,hover=list(INDUSTRY,EMP,PAYANN)) %>% y_axis(visible=FALSE) %>% x_axis(visible=FALSE)Result shows that annual payroll and employment in most states are not linear related. So that conclustion can be there is no direct connection between payroll and employment.
Payroll of interested industries
More detailed information about business is needed. Interactive map showed below displays selected industries’ payroll among different states. It is obvious to know that which industries are leading industries of different states.
leaflet(poly) %>% addTiles() %>%
addPolygons(label=paste(poly$name," (Agriculture=",poly$Agriculture,")"),
group = "Agriculture",
color = "#444444",
weight = 0.1,
smoothFactor = 0.5,
opacity = 1.0,
fillOpacity = 0.5,
fillColor = ~colorQuantile("YlOrRd", Agriculture)(Agriculture),
highlightOptions = highlightOptions(color = "white", weight = 2,
bringToFront = TRUE)) %>%
addPolygons(label=paste(poly$name," (Utilities=",poly$Utilities,")"),
group = "Utilities",
color = "#444444",
weight = 0.1,
smoothFactor = 0.5,
opacity = 1.0,
fillOpacity = 0.5,
fillColor = ~colorQuantile("YlOrRd", Utilities)(Utilities),
highlightOptions = highlightOptions(color = "white", weight = 2,
bringToFront = TRUE)) %>%
addPolygons(label=paste(poly$name," (Manufacturing=",poly$Manufacturing,")"),
group = "Manufacturing",
color = "#444444",
weight = 0.1,
smoothFactor = 0.5,
opacity = 1.0,
fillOpacity = 0.5,
fillColor = ~colorQuantile("YlOrRd", Manufacturing)(Manufacturing),
highlightOptions = highlightOptions(color = "white", weight = 2,
bringToFront = TRUE)) %>%
addPolygons(label=paste(poly$name," (Information=",poly$Information,")"),
group = "Information",
color = "#444444",
weight = 0.1,
smoothFactor = 0.5,
opacity = 1.0,
fillOpacity = 0.5,
fillColor = ~colorQuantile("YlOrRd", Information)(Information),
highlightOptions = highlightOptions(color = "white", weight = 2,
bringToFront = TRUE)) %>%
addPolygons(label=paste(poly$name," (HealthCare=",poly$HealthCare,")"),
group = "HealthCare",
color = "#444444",
weight = 0.1,
smoothFactor = 0.5,
opacity = 1.0,
fillOpacity = 0.5,
fillColor = ~colorQuantile("YlOrRd", HealthCare)(HealthCare),
highlightOptions = highlightOptions(color = "white", weight = 2,
bringToFront = TRUE)) %>%
addPolygons(label=paste(poly$name," (Arts=",poly$Arts,")"),
group = "Arts",
color = "#444444",
weight = 0.1,
smoothFactor = 0.5,
opacity = 1.0,
fillOpacity = 0.5,
fillColor = ~colorQuantile("YlOrRd", Arts)(Arts),
highlightOptions = highlightOptions(color = "white", weight = 2,
bringToFront = TRUE)) %>%
addLayersControl(
baseGroups = c("Agriculture", "Utilities","Manufacturing","Information","HealthCare","Arts"),
options = layersControlOptions(collapsed = FALSE)
)%>%
addMiniMap()Industries in New York State
Interesting phenomenan are found when some selected industries data of New York state is displayed. The first histogram displays annual payroll among different industries and the second displays employment among different industries. Some more information can be explored When comparing these two histograms. For some more analysis, please see the 4th point in the part Conclusions.
plot_ly(df2[which(df2$GEO_NAME=='New York'),],type="bar",x=~INDUSTRY,y=~PAYANN,color=~INDUSTRY) %>%
layout(xaxis = list(showline = F,
showticklabels = F,
fixedrange = T,
title = ""),
yaxis = list(visible=FALSE))plot_ly(df2[which(df2$GEO_NAME=='New York'),],type="bar",x=~INDUSTRY,y=~EMP,color=~INDUSTRY) %>%
layout(xaxis = list(showline = F,
showticklabels = F,
fixedrange = T,
title = ""),
yaxis = list(visible=FALSE))Spatial Autocorrelation of Information Industry
Information Industry is a special industry which is not limited too much by geographical factors when compared with traditional industries. But it could be more convincing to prove it with real data. Here only data of states in the continent US is anaylzed since only those states are geographical adjacent.
Main goal of the calculation below is to obtain the Moran’s I value and p-value which can be analyzed later to figure our whether information industry is spatial autocorrelated.
Adjacency is used as criterion to determine which polygons are “near” and to quantify that.
Function poly2nb is used to create the object of “neighbour”.
poly2 <- poly[-which(poly$name == 'Puerto Rico'|poly$name =='Alaska'|poly$name =='Hawaii'),]
head(data.frame(poly2))## id name density Agriculture Utilities Manufacturing Information
## 0 01 Alabama 94.65 18813 9097 4410 12510
## 2 04 Arizona 57.05 33876 3275 42194 24880
## 3 05 Arkansas 56.43 12750 35891 37379 5479
## 4 06 California 241.70 92 38488 39397 41722
## 5 08 Colorado 49.33 34460 42376 39105 38797
## 6 09 Connecticut 739.10 4366 42990 2047 25185
## HealthCare Arts
## 0 1956 23950
## 2 9504 8204
## 3 38140 12722
## 4 987 9754
## 5 6834 10977
## 6 5590 39265w <- poly2nb(poly2,row.names=poly2$id)
class(w)## [1] "nb"Plot the links between the polygons, the links actually show the data stored in variable w.
plot(poly2,col='gray',border='blue',lwd=2)
xy <- coordinates(poly2)
plot(w,xy,col='red',lwd=2,add=TRUE)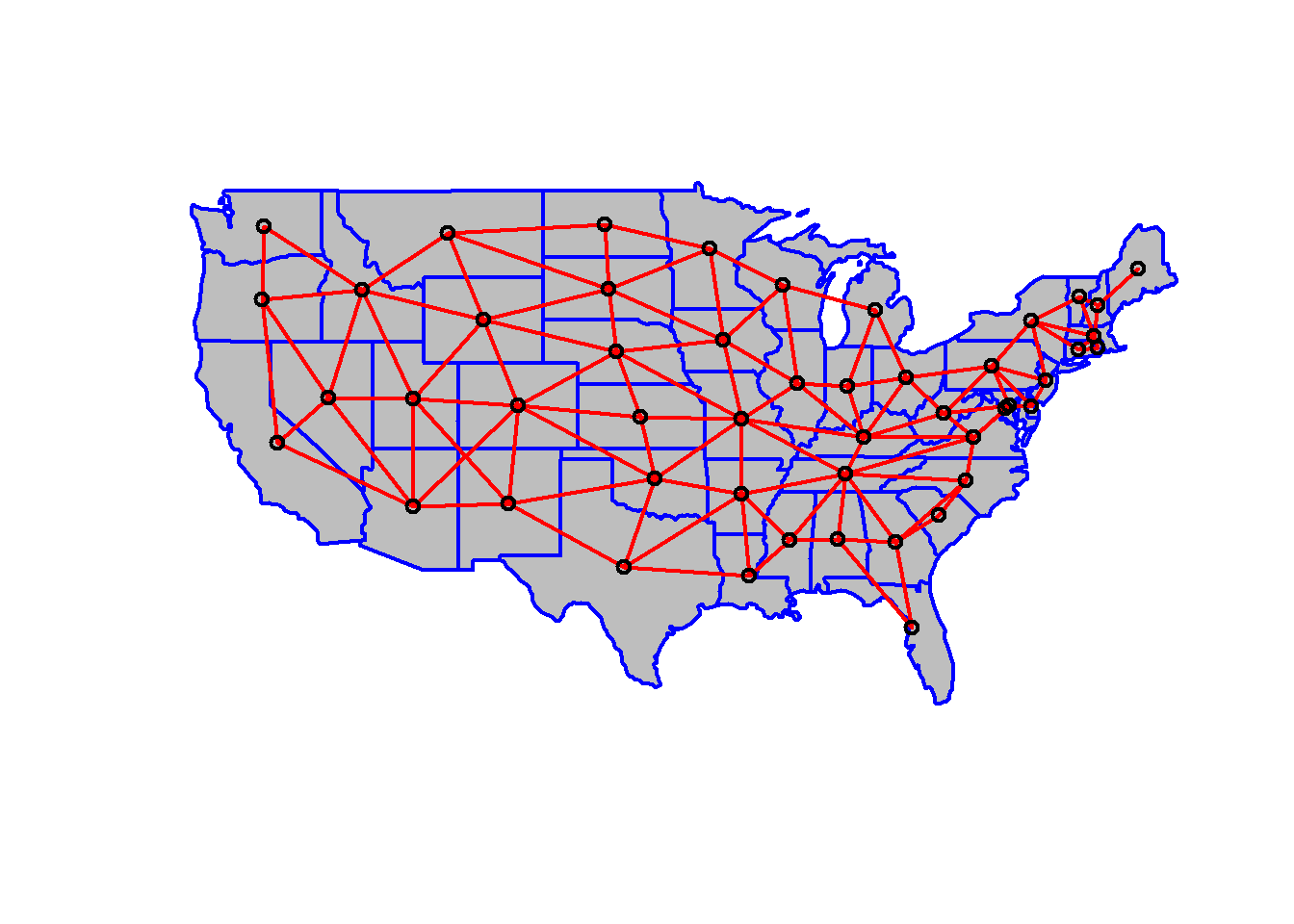
w can be transformed into a spatial weights matrix. A spatial weights matrix reflects the intensity of the geographic relationship between observations
wm <- nb2mat(w,style='B',zero.policy=TRUE)Now Moran’s index of spatial autocorrelation can be computed in terms of the formular listed below. 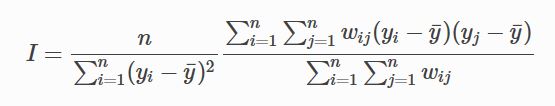
n<- length(poly2)
y <- poly2$Information
ybar <- mean(y)
dy <- y-ybar
g <- expand.grid(dy,dy)
yiyj <- g[,1]*g[,2]
pm <- matrix(yiyj,ncol=n)
pmw <- pm*wm
spmw <- sum(pmw)
spmw## [1] -4525772619smw <- sum(wm)
sw <- spmw/smw
vr <- n/sum(dy^2)
MI <- vr*sw
MI## [1] -0.1331731EI <- -1/(n-1)
EI## [1] -0.02083333ww <- nb2listw(w,style='B',zero.policy = TRUE)
print(ww,zero.policy=TRUE)## Characteristics of weights list object:
## Neighbour list object:
## Number of regions: 49
## Number of nonzero links: 218
## Percentage nonzero weights: 9.07955
## Average number of links: 4.44898
##
## Weights style: B
## Weights constants summary:
## n nn S0 S1 S2
## B 49 2401 218 436 4392As the rusult of Moran I is obtained (which equals to -0.133173133), function moran.test is used to verify.
moran.test(poly2$Information,ww,randomisation = FALSE,zero.policy = TRUE)##
## Moran I test under normality
##
## data: poly2$Information
## weights: ww
##
## Moran I statistic standard deviate = -1.2477, p-value = 0.8939
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## -0.133173133 -0.020833333 0.008107271Verification shows the rusult is correct and p value is obtained simultaneously. Analysis of the result will be conduct in the conclusion part.
Conclusions
Analysze the results above, it is obviously that:
1. Number of firms:
+ California, Texas, New York, Florida are on the top 4 on the rank of number of firms
2. Payroll and Employment:
+ California, Texas, New York, Florida are also the top 4 of the rank of both payroll and employment
3. Relationship between Payroll and Employment: No direct relationship
4. Industries in New York State:
+ Most industries are on the same level developed
+ Some industries like accommodation and television broadcasting are with little employment but large payroll
+ In contrast, some industries like agriculture, aircraft manufacturing and book stores are with relatively large emplyment but smaller payroll.
In terms of Moran’s theory about spatial autocorrelation, Moran’s I > 0 represents positive spatial autocorrelated and Moran’s I < 0 represents negative spatial autocorrelated. And when Moran’s I is close to zero, it represents value distributes spatial randomly.
As to value p, the treshold value is normally set as 0.05, if p is greater than threshold, the larger the value, the more evidence that the so-called null hypothesis can be approved, which indicates the value is randomly distributed.
In our case, MI= -0.1331731 is near to 0 and p=0.8939 is much larger than 0.05, so that we cannot reject the null hypothesis. It is quite possible that the spatial distribution of the scale of information industry is the result of random spatial processes.
References
[1] GE, Ying, et al. “Application of spatial autocorrelation for the spatial patterns of urbanization and localization economy [J].” Human Geography 3 (2005): 21-25.
[2] Juhn, Chinhui, and Simon Potter. “Explaining the recent divergence in payroll and household employment growth.” (1999).
[3] Shen, Chenhua, Chaoling Li, and Yali Si. “Spatio-temporal autocorrelation measures for nonstationary series: A new temporally detrended spatio-temporal Moran’s index.” Physics Letters A 380.1 (2016): 106-116.